一招制勝 數據處理提速5倍的金融企業數據開發秘訣
在競爭日益激烈的金融行業,數據處理速度往往直接決定企業的決策效率和市場反應能力。傳統的金融數據開發流程常常因技術堆棧復雜、數據孤島嚴重、計算資源調度不靈活等問題而步履維艱。僅僅通過引入并系統化應用一個核心策略,許多領先的金融機構已經成功地將數據開發效率提升了數倍,甚至達到驚人的5倍提速。這一招,就是全面擁抱并實施 “一體化云原生數據湖倉架構與低代碼/自動化數據流水線”。
核心策略解析
這一招并非單一工具,而是一個緊密結合的體系化方法:
1. 構建云原生數據湖倉(Lakehouse)作為統一基石
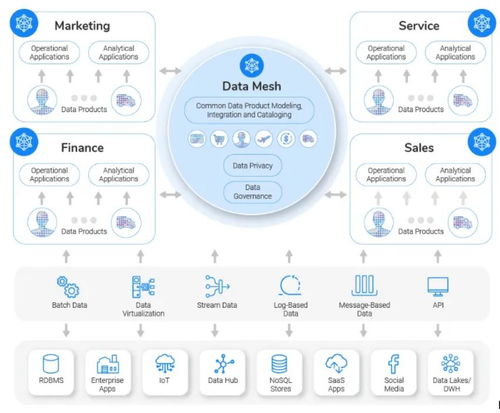
* 打破孤島,統一存儲: 告別過去交易數據、客戶行為數據、市場數據等分散在不同數據庫、數據倉庫和數據湖中的局面。利用云對象存儲(如AWS S3、Azure Blob Storage)的彈性與低成本優勢,構建一個能夠同時容納原始數據、清洗后數據、特征數據和模型數據的單一可信數據源。這消除了大量的數據搬遷和格式轉換時間。
- 事務與分析的統一: 采用Delta Lake、Apache Iceberg或Apache Hudi等開源表格式,在數據湖之上賦予ACID事務、數據版本管理、模式演進等數據倉庫級的管理能力。這意味著數據工程師和數據分析師可以在同一份實時更新的數據上工作,開發即用,無需等待漫長的ETL(抽取、轉換、加載)過程。
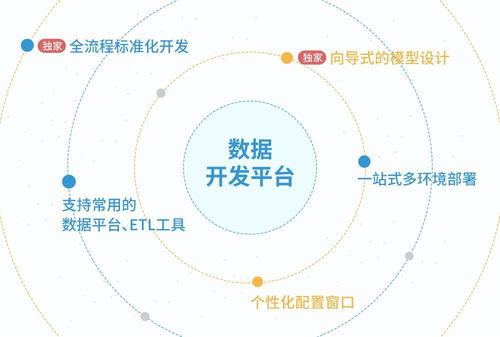
2. 部署低代碼/自動化數據流水線開發平臺
* 可視化編排,降低門檻: 利用如Apache Airflow、Prefect或云廠商提供的托管工作流服務(如AWS Step Functions, Google Cloud Composer),通過拖拽和配置的方式,直觀地設計復雜的數據依賴關系與處理流程。業務分析師和初級數據開發者也能快速參與構建數據產品,極大釋放了資深數據工程師的生產力。
- 智能調度與監控: 平臺自動處理任務調度、依賴管理、錯誤重試和報警通知。開發者從繁瑣的運維工作中解放出來,專注于核心的業務邏輯開發。
- 模板化與可復用組件: 將常見的金融數據處理模式(如市價重估、風險因子計算、客戶分群、反欺詐特征生成)封裝成可復用的標準化組件或模板。新項目的開發不再是“從零開始”,而是“積木式搭建”,這是實現5倍提速的關鍵杠桿點。
提速5倍的效果體現
- 開發周期極速縮短: 過去需要一個團隊耗時數周才能上線的新數據報表或模型特征,現在可能由1-2人在幾天內完成。需求響應從“月”級進入“天”甚至“小時”級。
- 運維復雜度斷崖式下降: 統一的架構和自動化流水線,使得系統監控、問題排查和數據血緣追溯變得異常清晰,將運維負擔降低了70%以上。
- 資源利用效率飆升: 云原生架構支持計算與存儲分離,以及彈性伸縮。數據處理任務可以按需申請大量資源快速完成,然后立即釋放,避免了本地集群常年的資源閑置與排隊等待,計算成本反而可能下降。
- 協同效率大幅提升: 數據科學家、分析師、工程師在統一、實時、可信的數據基底上協作,溝通成本降低,迭代速度加快。
實施路徑建議
- 評估與規劃: 盤點現有數據資產與技術棧,選擇最適合自身云環境和團隊的Lakehouse表格式與自動化調度工具。從小型但關鍵的業務場景(如每日監管報表自動化)開始試點。
- 搭建核心平臺: 建立統一的云數據存儲層,部署工作流調度平臺,并著手將最耗時、最重復的數據處理任務遷移和重構。
- 沉淀與賦能: 在實戰中,不斷將最佳實踐沉淀為標準化組件和模板,建立內部知識庫,并對團隊進行系統化培訓,推廣低代碼開發文化。
- 迭代與擴展: 將成功模式復制到更多的業務線,并持續優化平臺能力,例如集成數據質量管理、數據目錄等,形成完整的數據中臺能力。
結論
對于金融企業而言,數據開發的競爭本質上是一場效率的競爭。“一體化云原生數據湖倉架構與低代碼/自動化數據流水線”這一組合策略,通過技術架構的統一化和開發過程的自動化、模板化,直擊傳統開發模式的痛點。它不僅僅是技術的升級,更是工作模式和協作方式的革新。成功實施這一招,金融企業收獲的將不僅是5倍的數據開發速度提升,更是構筑未來數據驅動智能決策的堅實核心能力。
如若轉載,請注明出處:http://www.gzdazhongbj.com.cn/product/45.html
更新時間:2026-02-23 22:21:27