一文讀懂?dāng)?shù)據(jù)架構(gòu)選擇與數(shù)據(jù)處理優(yōu)化
在當(dāng)今數(shù)字化時(shí)代,數(shù)據(jù)已成為企業(yè)的核心資產(chǎn)。合理選擇數(shù)據(jù)架構(gòu)并高效處理數(shù)據(jù),是釋放數(shù)據(jù)價(jià)值、支撐業(yè)務(wù)創(chuàng)新的關(guān)鍵。本文將系統(tǒng)性地解析數(shù)據(jù)架構(gòu)的核心類型與選擇策略,并探討數(shù)據(jù)處理中的核心考量因素,為您的數(shù)據(jù)決策提供清晰指引。
一、 主流數(shù)據(jù)架構(gòu)類型解析
數(shù)據(jù)架構(gòu)定義了如何組織、存儲(chǔ)、集成和管理數(shù)據(jù)資產(chǎn)。了解主流架構(gòu)是選擇的第一步:
- 傳統(tǒng)數(shù)據(jù)倉庫(Data Warehouse, DWH):
- 核心特征:面向主題的、集成的、非易失的、隨時(shí)間變化的數(shù)據(jù)集合。通常采用維度建模(星型/雪花型模式)。
- 適用場景:需要強(qiáng)一致性、穩(wěn)定模式、支持復(fù)雜BI報(bào)表和歷史趨勢分析的企業(yè)級(jí)結(jié)構(gòu)化數(shù)據(jù)分析。
- 技術(shù)代表:Teradata, IBM Netezza, Greenplum等。
- 數(shù)據(jù)湖(Data Lake):
- 核心特征:集中存儲(chǔ)海量原始數(shù)據(jù)的存儲(chǔ)庫,格式多樣(結(jié)構(gòu)化、半結(jié)構(gòu)化、非結(jié)構(gòu)化)。遵循“先存儲(chǔ),后處理”模式。
- 適用場景:需要存儲(chǔ)海量原始數(shù)據(jù)(如日志、IoT數(shù)據(jù)、音視頻)、進(jìn)行探索性分析、機(jī)器學(xué)習(xí)模型訓(xùn)練等。
- 技術(shù)代表:Hadoop HDFS, Amazon S3, Azure Data Lake Storage等。
- 湖倉一體(Lakehouse):
- 核心特征:融合數(shù)據(jù)湖的低成本、靈活性(存儲(chǔ)原始數(shù)據(jù))與數(shù)據(jù)倉庫的事務(wù)支持、數(shù)據(jù)管理和性能優(yōu)化能力。旨在實(shí)現(xiàn)“一份數(shù)據(jù),多種工作負(fù)載”。
- 適用場景:現(xiàn)代數(shù)據(jù)平臺(tái)的主流選擇,同時(shí)需要支持BI分析、數(shù)據(jù)科學(xué)、實(shí)時(shí)應(yīng)用等多種負(fù)載。
- 技術(shù)代表:Databricks Delta Lake, Apache Hudi, Snowflake等。
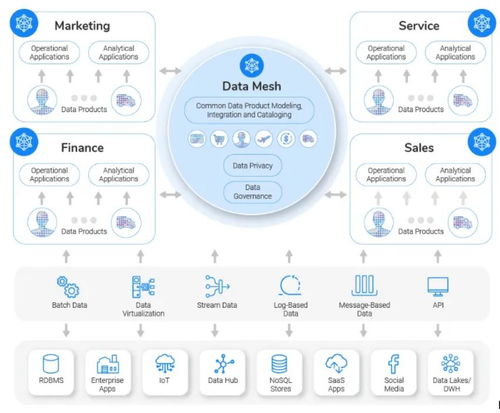
- 數(shù)據(jù)網(wǎng)格(Data Mesh):
- 核心特征:一種去中心化的社會(huì)技術(shù)架構(gòu)范式。將數(shù)據(jù)視為產(chǎn)品,由領(lǐng)域團(tuán)隊(duì)負(fù)責(zé),強(qiáng)調(diào)數(shù)據(jù)所有權(quán)、自治和自服務(wù)基礎(chǔ)設(shè)施。
- 適用場景:大型復(fù)雜組織,需要解決數(shù)據(jù)孤島、提升數(shù)據(jù)產(chǎn)品化能力和團(tuán)隊(duì)敏捷性。
- 實(shí)施要點(diǎn):更多是一種組織與架構(gòu)哲學(xué),需要配套的技術(shù)平臺(tái)支持。
二、 如何選擇合適的數(shù)據(jù)架構(gòu)?關(guān)鍵考量因素
選擇并非非此即彼,而常是組合與演進(jìn)。決策應(yīng)基于以下核心維度:
- 數(shù)據(jù)特征與來源:
- 數(shù)據(jù)量級(jí):TB級(jí)還是PB/EB級(jí)?數(shù)據(jù)湖和湖倉一體更適合海量數(shù)據(jù)。
- 數(shù)據(jù)類型:主要是規(guī)整的結(jié)構(gòu)化數(shù)據(jù),還是包含大量文本、圖像、日志?后者需要數(shù)據(jù)湖的靈活性。
- 數(shù)據(jù)速度:批處理為主,還是有實(shí)時(shí)/流式數(shù)據(jù)需求?實(shí)時(shí)性要求高的場景需要引入流處理架構(gòu)(如Kafka, Flink)。
- 業(yè)務(wù)需求與用例:
- 分析類型:是固定的歷史報(bào)表(適合數(shù)據(jù)倉庫),還是探索性的數(shù)據(jù)科學(xué)(適合數(shù)據(jù)湖/湖倉一體)?
- 用戶角色:服務(wù)于業(yè)務(wù)分析師(需要SQL和穩(wěn)定模型)、數(shù)據(jù)科學(xué)家(需要原始數(shù)據(jù)和靈活工具)還是應(yīng)用程序(需要API和低延遲)?
- 一致性要求:是否需要強(qiáng)ACID事務(wù)保證(湖倉一體和現(xiàn)代數(shù)據(jù)倉庫支持更好)?
- 技術(shù)成熟度與成本:
- 團(tuán)隊(duì)技能:團(tuán)隊(duì)更熟悉傳統(tǒng)SQL生態(tài),還是具備分布式系統(tǒng)(如Hadoop/Spark)開發(fā)運(yùn)維能力?
- 總擁有成本(TCO):考慮存儲(chǔ)成本、計(jì)算成本、開發(fā)維護(hù)成本。云托管服務(wù)(如Snowflake, BigQuery, Azure Synapse)可降低運(yùn)維復(fù)雜度。
- 現(xiàn)有技術(shù)棧:需考慮與現(xiàn)有系統(tǒng)的集成和遷移路徑。
- 未來擴(kuò)展性與演進(jìn):
- 架構(gòu)是否易于擴(kuò)展以容納新的數(shù)據(jù)源和業(yè)務(wù)需求?
- 是否支持從傳統(tǒng)批處理向?qū)崟r(shí)分析、AI/ML應(yīng)用的平滑演進(jìn)?
- 推薦路徑:對于大多數(shù)現(xiàn)代企業(yè),從構(gòu)建一個(gè)以湖倉一體為核心的現(xiàn)代化數(shù)據(jù)平臺(tái)開始,是一個(gè)穩(wěn)健且面向未來的選擇,它提供了足夠的靈活性和性能。
三、 數(shù)據(jù)處理:架構(gòu)落地的關(guān)鍵環(huán)節(jié)
確定了宏觀架構(gòu),高效的數(shù)據(jù)處理管道是價(jià)值實(shí)現(xiàn)的引擎。數(shù)據(jù)處理主要包括:
- 數(shù)據(jù)集成與攝取:
- 批處理:定期(如每日)從源系統(tǒng)(數(shù)據(jù)庫、ERP等)全量或增量抽取數(shù)據(jù)。工具如Sqoop, DataX,或云服務(wù)的Data Pipeline。
- 流處理:實(shí)時(shí)捕獲數(shù)據(jù)變更(CDC)或消息隊(duì)列數(shù)據(jù)。工具如Debezium, Apache Kafka, Flink。
- 數(shù)據(jù)存儲(chǔ)與管理:
- 分層設(shè)計(jì):常分為原始層(Raw)、清洗整合層(Cleansed/Integrated)、匯總應(yīng)用層(Aggregated/Curated)。確保數(shù)據(jù)血緣清晰,質(zhì)量可控。
- 數(shù)據(jù)格式:列式存儲(chǔ)格式(如Parquet, ORC)因其高壓縮比和查詢性能,已成為湖倉場景的事實(shí)標(biāo)準(zhǔn)。
- 數(shù)據(jù)轉(zhuǎn)換與計(jì)算:
- ETL vs ELT:現(xiàn)代趨勢是ELT——先將原始數(shù)據(jù)加載到強(qiáng)大的存儲(chǔ)引擎(如數(shù)據(jù)湖倉),再利用其計(jì)算能力進(jìn)行轉(zhuǎn)換。這提高了靈活性。
- 計(jì)算引擎:根據(jù)場景選擇。復(fù)雜批處理用Spark,交互式查詢用Presto/Trino,流處理用Flink,云上可考慮Serverless引擎(如BigQuery, Snowflake)。
- 數(shù)據(jù)服務(wù)與治理:
- 數(shù)據(jù)服務(wù)化:通過API、數(shù)據(jù)市場或BI工具,將處理好的數(shù)據(jù)安全、高效地交付給消費(fèi)方。
- 數(shù)據(jù)治理:貫穿始終,包括元數(shù)據(jù)管理、數(shù)據(jù)質(zhì)量監(jiān)控、數(shù)據(jù)安全與隱私保護(hù)(脫敏、加密)、數(shù)據(jù)血緣追溯。這是架構(gòu)長期健康運(yùn)行的保障。
四、 與實(shí)踐建議
選擇數(shù)據(jù)架構(gòu)沒有“銀彈”,核心在于匹配自身現(xiàn)狀與目標(biāo)。一個(gè)實(shí)用的建議路徑是:
- 明確目標(biāo):從最迫切的1-2個(gè)業(yè)務(wù)用例出發(fā),定義清晰的成功標(biāo)準(zhǔn)(如:報(bào)表速度提升X倍,支持實(shí)時(shí)風(fēng)控)。
- 從簡開始,迭代演進(jìn):可以從云上的托管湖倉一體服務(wù)開始搭建最小可行數(shù)據(jù)平臺(tái),避免過度設(shè)計(jì)。例如,使用S3存儲(chǔ)原始數(shù)據(jù),利用Spark或云原生服務(wù)進(jìn)行ETL,通過BI工具連接進(jìn)行展示。
- 強(qiáng)化數(shù)據(jù)治理基礎(chǔ):在早期就建立基本的元數(shù)據(jù)管理和數(shù)據(jù)質(zhì)量檢查規(guī)則,為后續(xù)擴(kuò)展打下基礎(chǔ)。
- 擁抱開放標(biāo)準(zhǔn)與云原生:優(yōu)先選擇支持開放格式(Parquet, Iceberg等)和開放接口的技術(shù),避免廠商鎖定,保持架構(gòu)靈活性。
- 關(guān)注組織與人才:技術(shù)架構(gòu)的成功最終依賴于組織架構(gòu)和團(tuán)隊(duì)能力。培養(yǎng)數(shù)據(jù)產(chǎn)品思維,促進(jìn)業(yè)務(wù)與數(shù)據(jù)團(tuán)隊(duì)的緊密協(xié)作。
通過系統(tǒng)性地評(píng)估需求、理解架構(gòu)選項(xiàng)、并構(gòu)建穩(wěn)健的數(shù)據(jù)處理流程,企業(yè)可以構(gòu)建一個(gè)既能滿足當(dāng)前需求,又具備強(qiáng)大演進(jìn)能力的數(shù)據(jù)基石,從而在數(shù)據(jù)驅(qū)動(dòng)的競爭中贏得先機(jī)。
如若轉(zhuǎn)載,請注明出處:http://www.gzdazhongbj.com.cn/product/53.html
更新時(shí)間:2026-02-23 10:48:39