深入剖析Hadoop框架 大數(shù)據(jù)處理的基石
Hadoop是一個(gè)開(kāi)源分布式計(jì)算框架,由Apache軟件基金會(huì)開(kāi)發(fā),旨在從單一服務(wù)器擴(kuò)展到數(shù)以千計(jì)的機(jī)器,每臺(tái)機(jī)器都提供本地計(jì)算和存儲(chǔ)。其核心設(shè)計(jì)靈感來(lái)源于Google的MapReduce和Google File System(GFS)論文,為海量數(shù)據(jù)的存儲(chǔ)和處理提供了一個(gè)可靠、可擴(kuò)展的平臺(tái)。
一、Hadoop的核心組件
Hadoop生態(tài)系統(tǒng)主要由兩個(gè)核心組件構(gòu)成:Hadoop Distributed File System(HDFS)和MapReduce。
- HDFS(Hadoop分布式文件系統(tǒng))
- 設(shè)計(jì)目標(biāo):用于在廉價(jià)硬件上存儲(chǔ)超大規(guī)模數(shù)據(jù)集,并提供高吞吐量的數(shù)據(jù)訪問(wèn)。
- 架構(gòu):采用主從(Master/Slave)架構(gòu)。
- NameNode(主節(jié)點(diǎn)):管理文件系統(tǒng)的命名空間(元數(shù)據(jù)),如文件名、目錄結(jié)構(gòu)、文件塊位置等。一個(gè)集群通常只有一個(gè)活躍的NameNode,負(fù)責(zé)協(xié)調(diào)客戶端對(duì)文件的訪問(wèn)。
- DataNode(從節(jié)點(diǎn)):存儲(chǔ)實(shí)際的數(shù)據(jù)塊。集群中有多個(gè)DataNode,它們負(fù)責(zé)響應(yīng)客戶端的讀寫請(qǐng)求,并執(zhí)行來(lái)自NameNode的塊創(chuàng)建、刪除和復(fù)制指令。
- 數(shù)據(jù)復(fù)制:HDFS通過(guò)將文件分割成固定大小的塊(默認(rèn)128MB或256MB)并在多個(gè)DataNode上復(fù)制(默認(rèn)3份)來(lái)實(shí)現(xiàn)容錯(cuò)性。即使某個(gè)節(jié)點(diǎn)故障,數(shù)據(jù)也不會(huì)丟失。
- MapReduce(分布式計(jì)算模型)
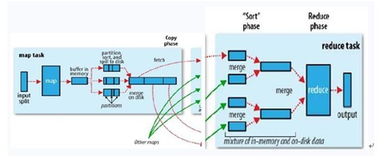
- 編程模型:將計(jì)算任務(wù)分為兩個(gè)主要階段——Map(映射)和Reduce(歸約)。
- Map階段:輸入數(shù)據(jù)被分割成獨(dú)立的塊,由多個(gè)Map任務(wù)并行處理。每個(gè)Map任務(wù)處理一個(gè)數(shù)據(jù)塊,并輸出一組中間鍵值對(duì)(key-value pairs)。
- Shuffle與Sort階段:系統(tǒng)自動(dòng)將Map輸出的中間結(jié)果根據(jù)key進(jìn)行排序和分組,然后分發(fā)到相應(yīng)的Reduce任務(wù)節(jié)點(diǎn)。此過(guò)程對(duì)用戶透明,但至關(guān)重要。
- Reduce階段:每個(gè)Reduce任務(wù)接收屬于特定key的所有中間值,對(duì)其進(jìn)行歸約(如求和、計(jì)數(shù)、聚合等),并產(chǎn)生最終輸出。
- 執(zhí)行框架:由JobTracker(主節(jié)點(diǎn),負(fù)責(zé)調(diào)度和監(jiān)控作業(yè))和TaskTracker(從節(jié)點(diǎn),執(zhí)行具體任務(wù))管理。在Hadoop 2.x及以后版本中,被更通用的資源管理框架YARN所取代。
二、Hadoop的數(shù)據(jù)處理流程(以經(jīng)典MapReduce為例)
一次完整的數(shù)據(jù)處理作業(yè)通常遵循以下步驟:
- 輸入與分片:客戶端提交作業(yè),輸入數(shù)據(jù)(通常存儲(chǔ)在HDFS上)被邏輯劃分為多個(gè)InputSplit(輸入分片)。每個(gè)分片由一個(gè)Map任務(wù)處理。
- Map階段:多個(gè)Map任務(wù)并行啟動(dòng)。每個(gè)任務(wù)讀取其分配的分片,逐條記錄應(yīng)用用戶定義的
map()函數(shù),生成中間鍵值對(duì)并寫入本地磁盤。 - Shuffle與Sort:這是MapReduce的“心臟”。Map任務(wù)完成后,其輸出根據(jù)key進(jìn)行分區(qū)(決定由哪個(gè)Reduce處理),然后通過(guò)HTTP被對(duì)應(yīng)的Reduce任務(wù)拉取(Fetch)。在Reduce端,來(lái)自所有Map任務(wù)的、屬于同一分區(qū)的數(shù)據(jù)會(huì)按鍵進(jìn)行排序和合并。
- Reduce階段:排序后的中間數(shù)據(jù)被輸入用戶定義的
reduce()函數(shù)。Reduce任務(wù)對(duì)每個(gè)唯一的key及其對(duì)應(yīng)的值列表進(jìn)行處理,產(chǎn)生最終結(jié)果。 - 輸出:Reduce的輸出通常寫回HDFS,每個(gè)Reduce任務(wù)生成一個(gè)獨(dú)立的輸出文件。
三、Hadoop的優(yōu)勢(shì)
- 高可靠性:數(shù)據(jù)多副本存儲(chǔ)和計(jì)算任務(wù)自動(dòng)重試機(jī)制,保障了硬件故障下的數(shù)據(jù)安全與任務(wù)完成。
- 高可擴(kuò)展性:可通過(guò)簡(jiǎn)單地增加商用服務(wù)器節(jié)點(diǎn)來(lái)線性擴(kuò)展集群的存儲(chǔ)和計(jì)算能力。
- 高容錯(cuò)性:能夠自動(dòng)處理節(jié)點(diǎn)故障,將失敗的任務(wù)重新調(diào)度到其他健康節(jié)點(diǎn)執(zhí)行。
- 成本效益:構(gòu)建在廉價(jià)的商用硬件集群上,降低了海量數(shù)據(jù)存儲(chǔ)與處理的成本。
- 適合批處理:尤其擅長(zhǎng)處理離線、海量的歷史數(shù)據(jù)集,進(jìn)行復(fù)雜的批量分析和ETL(提取、轉(zhuǎn)換、加載)操作。
四、Hadoop生態(tài)系統(tǒng)的演進(jìn)與補(bǔ)充
隨著大數(shù)據(jù)技術(shù)的發(fā)展,Hadoop的核心MapReduce因其磁盤I/O開(kāi)銷大、延遲高等問(wèn)題,在某些場(chǎng)景下(如交互式查詢、流處理)顯得力不從心。因此,以YARN(Yet Another Resource Negotiator)為核心的Hadoop 2.x應(yīng)運(yùn)而生。
- YARN:將資源管理與作業(yè)調(diào)度/監(jiān)控功能分離,成為一個(gè)通用的集群資源管理平臺(tái)。這使得Hadoop可以運(yùn)行除MapReduce之外的其他計(jì)算框架,如:
- Apache Spark:基于內(nèi)存計(jì)算的快速通用引擎,支持流處理、SQL查詢、機(jī)器學(xué)習(xí)和圖計(jì)算,常作為MapReduce的替代或補(bǔ)充。
- Apache Hive:提供SQL接口(HiveQL)將查詢轉(zhuǎn)換為MapReduce/Tez/Spark作業(yè),用于數(shù)據(jù)倉(cāng)庫(kù)匯總和查詢。
- Apache HBase:建立在HDFS之上的分布式、可擴(kuò)展的NoSQL數(shù)據(jù)庫(kù),支持實(shí)時(shí)讀寫隨機(jī)訪問(wèn)。
- Apache Flink:統(tǒng)一的流批處理計(jì)算框架。
- Apache Tez:旨在加速Hive、Pig等作業(yè)執(zhí)行的DAG(有向無(wú)環(huán)圖)計(jì)算框架。
五、與展望
Hadoop框架,特別是其HDFS和YARN,構(gòu)成了現(xiàn)代大數(shù)據(jù)平臺(tái)的基石。其核心思想——將計(jì)算移至數(shù)據(jù)所在位置、通過(guò)數(shù)據(jù)冗余實(shí)現(xiàn)容錯(cuò)——深刻影響了后續(xù)的大數(shù)據(jù)技術(shù)發(fā)展。盡管原生MapReduce在實(shí)時(shí)性要求高的場(chǎng)景中使用減少,但整個(gè)Hadoop生態(tài)系統(tǒng)通過(guò)集成Spark、Flink等更高效的計(jì)算引擎,以及Hive、HBase等上層工具,依然在企業(yè)級(jí)數(shù)據(jù)湖、大規(guī)模批處理、歷史數(shù)據(jù)分析等領(lǐng)域發(fā)揮著不可替代的作用。理解Hadoop的基本原理,是深入大數(shù)據(jù)技術(shù)領(lǐng)域的必備基礎(chǔ)。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.gzdazhongbj.com.cn/product/56.html
更新時(shí)間:2026-02-23 21:21:02