駕馭數據洪流 海量數據處理的五大核心技巧
在當今大數據時代,企業、研究機構乃至個人都面臨著數據規模呈指數級增長的挑戰。海量數據處理(Massive Data Processing)已不再是技術領域的專屬議題,而是成為一項關乎效率、洞察與決策的關鍵能力。面對TB甚至PB級別的數據,傳統的處理方式往往力不從心。本文將系統性地介紹五大核心技巧,幫助您高效、精準地駕馭數據洪流。
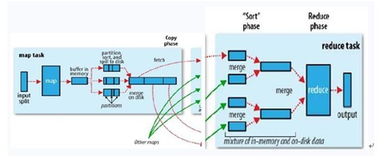
一、 分而治之:分布式計算框架的應用
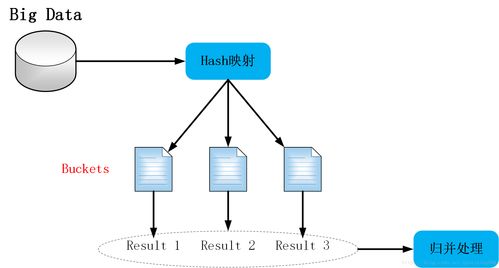
這是處理海量數據的基石。核心思想是將一個龐大的數據集分割成多個較小的、可獨立處理的子集,分布在多個計算節點上并行處理,最后將結果匯總。代表性技術包括:
- Hadoop MapReduce:經典的批處理模型,適合對離線數據進行復雜的轉換與分析。
- Apache Spark:憑借其內存計算和DAG執行引擎,在迭代計算和交互式查詢上性能遠超MapReduce,成為當前主流。
- Flink:專注于流處理的低延遲、高吞吐框架,真正實現了流批一體。
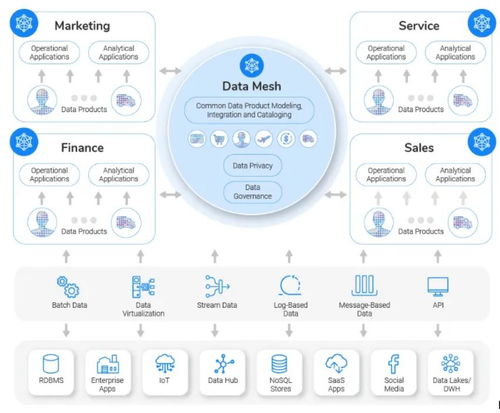
二、 優化存儲:選擇合適的數據存儲方案
數據存儲的效率直接決定了處理的性能。針對海量數據,需打破傳統關系型數據庫的思維定式:
- 分布式文件系統:如HDFS,提供高容錯性、高吞吐量的數據存儲基礎。
- NoSQL數據庫:根據數據模型(鍵值、文檔、列族、圖)選擇MongoDB、Cassandra、HBase等,以犧牲部分事務特性換取水平擴展性和靈活模式。
- 數據湖/湖倉一體:將原始數據以原生格式(如Parquet、ORC)集中存儲,支持結構化和非結構化數據,為后續多樣化的分析提供原料。
三、 算法與數據結構優化
在單機或單個任務層面,精巧的算法能極大提升效率:
- Bloom Filter(布隆過濾器):用于快速判斷一個元素是否可能存在于一個超大集合中,能以極小的空間代價過濾掉大量不必要的磁盤查找。
- 哈希與分區:通過合理的哈希函數將數據均勻分布,避免數據傾斜(某些節點負載過重)。
- 聚合與采樣:在允許一定誤差的場景下,對數據進行聚合或隨機采樣,能大幅減少待處理的數據量,快速獲得趨勢性結論。
四、 增量處理與流處理
并非所有數據都需要全量重新計算:
- 增量計算:只對新增或變化的數據進行處理,并更新原有結果,避免重復計算。
- 流式處理:使用Kafka、Pulsar等消息隊列承接數據流,并利用Spark Streaming、Flink等框架進行實時處理,實現從“T+1”到“秒級/毫秒級”的洞察。
五、 資源管理與監控調優
海量數據處理是資源密集型任務,良好的管理至關重要:
- 資源調度:利用YARN、Kubernetes等資源管理器,公平、高效地在多個任務間分配集群的CPU、內存資源。
- 性能監控與調優:密切關注任務執行時間、數據傾斜情況、GC頻率等指標。通過調整分區數、并行度、緩存策略、序列化方式等參數,持續優化處理性能。
****
處理海量數據沒有“銀彈”,關鍵在于根據數據特性(體積、速度、多樣性)、業務需求(實時性、準確性)和技術棧,靈活組合運用上述技巧。從宏觀的架構選型到微觀的算法優化,構建一個層次分明、彈性可擴展的數據處理管道,方能在數據的海洋中從容航行,挖掘出真正的價值所在。
如若轉載,請注明出處:http://www.gzdazhongbj.com.cn/product/57.html
更新時間:2026-02-23 12:33:51